
shegenn Ред. 11.01.2023
Оценка качества признакового пространства и методология научного познания
Общеизвестно, что вопрос о выборе признаков при построении классификационного правила в задачах Data Mining (DM) и Big Data (BD), является одним из важнейших. В то же время, этот выбор, как правило, осуществляется в рамках общей, достаточно известной модели познания, хотя это не всегда осознается. При этом выбор системы признаков для описания объектов напрямую влияет на качество обучающей выборки (ОВ). Активное применение методов DM и BD ставит новые вопросы, касающиеся того, правильно ли понимаются их возможности и что может быть в них улучшено с точки зрения научного познания.
Цель исследования: в рамках методологии научного познания предложить оценку качества ОВ и соответствующего признакового пространства. Это позволит повысить эффективность применения методов DM и BD как специалистами в этой области, так и широкими кругами профессионалов в различных других областях, которым необходим интеллектуальный анализ эмпирических данных.
Вступление
Как известно, конечным продуктом любой науки являются Знания. Их добыча и переработка – основная задача нынешнего экономического уклада, получившего название экономики знаний (ЭЗ). Получение знаний соответствует известной модели познания: «от живого созерцания к абстракции и от нее к практике», в которой представлены 3 составляющие этой модели. Очевидно, начальные шаги при решении любой задачи должны отталкиваться от 1-ой составляющей. На важность этого этапа, именно на вычленении более детальной структуры процесса познания указывалось в работах [1-3] и др. С точки зрения методов Data Mining (DM) и Big Data (BD), этот этап соответствует поиску признакового пространства обучающей выборки (ОВ). И, наоборот, с точки зрения методов познания, подбор признаков ОВ фактически представляет собой 1-й этап общей модели познания.
Структуризация – начало любого исследования, без выделения соответствующих признаков она невозможна. Поэтому признаки необходимо выделять практически в любых задачах. Особенно это актуально для методов DM и BD, составляющих костяк наук, определяющих успех многих компаний, реализующих свое инновационное развитие на пути становления ЭЗ.
В методах DM и BD этап выделения признаков в виде некоторого инструментария не входит в арсенал ее средств – он отдан на откуп исследователям-предметникам, опирающихся при этом на свой опыт и интуицию. В то же время этот этап является одним из решающих, так как от правильного выбора признаков зачастую зависит весь успех решения задач DM и BD.
Основная трудность решения этой проблемы заключается в том, что не существует формальных правил, позволяющих заранее, априори, указать такой набор признаков, с помощью которого можно проводить классификацию с заданной точностью. В то же время желательно знать качество ОВ, а, следовательно, и признаков, входящих в эту ОВ еще в процессе ее создания, на этапе подготовки и сбора данных, поскольку это позволит в какой-то мере управлять этим процессом. Т.е. это важнейший этап подготовки данных, практически не поддающийся в настоящее время никакой формализации и оттого вдвойне важный.
Основная часть
В настоящее время фактически единственным способом оценки качества ОВ в общем случае является оценка, полученная на основе точности найденного при обучении решающего правила (РП), которая, как правило, определяется вероятностью правильного распознавания наборов ОВ построенным классификатором - РП. Однако получение такой оценки требует проведения процедуры обучения, а, следовательно, и, возможных значительных затрат времени [4]. В то же время желательно знать качество ОВ, не проводя самого обучения и получения РП, а также дать ее интерпретацию, в том числе указать, какие предельные возможности по различимости объектов существуют в данной выборке. Дополнительный анализ ОВ должен указать информативные признаки и выдать конструктивные рекомендации по улучшению основного качества ОВ – ее различительной способности.
Отметим, что в работе [5] сделана попытка оценить качество ОВ для построения прогнозирующей нейронной сети. Однако выдвинутые для такой оценки требования к ОВ снижают эффект от ее применения и не дают возможность оценить качество ОВ для более общих случаев, которые значительно чаще встречаются на практике.
Мы предлагаем восполнить этот пробел и подойти к выбору признаков ОВ более осознанно и с формализованных позиций. В частности, для формализации 1-го этапа указанного выше процесса познания предлагается использовать Процедуру 1, которая переводит 1-й шаг этой модели в конструктивную схему, позволяющую получить информационную картину, ландшафт задачи. Одновременно эта схема в случае ДМ демонстрирует и формализует этап подготовки и фиксации признакового пространства.
Ниже приведено ее описание.
Процедура 1 – обобщенное описание ландшафта задачи.
- Проводится качественно «созерцательный» анализ задачи и тех факторов, признаков или понятий, которые в ней присутствуют.
- Исходя из анализа задачи и целей исследования, описывается ландшафт задачи, т.е. все те факторы, признаки, которые могут оказать влияние или которые "окружают" задачу.
- В этом ландшафте отбираются или выделяются признаки, которые, по мнению исследователя, являются решающими в оказании влияния или определяющих свойства данного понятия и далее проводится их обоснование или доказательство, что они являются таковыми.
- Отобранные признаки Пi представляются затем или записываются в следующем формальном виде < П1, П2, ... П3 >.
По сути, Процедура 1 представляет собой инструмент исследования, позволяющий заинтересованным сторонам получить информационную картину, представление задачи для целей построения интересующей соответствующей модели.
Следующим этапом при решении задач DM и BD является сбор данных на основе отобранных признаков ОВ. Зависимость качества ОВ от собранных на предыдущем этапе признаков несомненна. Основой для построения, в указанном выше смысле, оценки качества ОВ, на наш взгляд, могут послужить фундаментальные исследования М.Кендалла и А.Стьюарта в области непараметрических задач статистики [6].
На основе этого подхода нами предлагается следующий способ вычисления оценки качества ОВ, преимуществом которого является относительная простота и «прозрачность» расчетов. Такая оценка вычисляется непосредственно по данным ОВ и характеризует различительную способность ОВ.
Оценка имеет следующий вид:
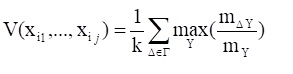 (1),
(1),
где k - число классов,
mY - число объектов, принадлежащих классу Y,
= ti1,ti2, … ,tij (0≤tij≤kij-1), j=1,…,- произвольный набор значений признаков (1≤≤ n),
- количество наборов выборки из m-го класса, для которых выполняется соотношение xij=tij (j=1,…,), tij – значение признаков xij в наборе , - множество всех наборов значений признаков .
Можно показать, что 1/k ≤ ≤1. Предельное значение, равное 1 эта оценка принимает при полной различимости классов, что было доказано в [7]. Таким образом, формула (1) при = n может служить оценкой качества ОВ, т.е если =1, то это означает, что имеет место полная различимость классов ОВ. Такой подход к оценке качества ОВ позволяет оптимизировать этапы обработки информации: если после вычисления по формуле (1) при = n оценка принимает значение 1 (или близкое к 1), то можно проводить дальнейшую классификационную обработку данных, которая наверняка приведет к РП с максимально возможной для данной выборки различительной способностью, близкой к полной различимости (по крайней мере, при использовании всего набора признаков). В противном случае необходимо либо привлечь дополнительные признаки, либо отказаться от имеющихся признаков и заменить их другими (возможно, проделать все это в некотором цикле).
В то же время можно также оценить информативность (важность, качество) P(xi) отдельного признака, привлекая для этой цели формулу (1) следующим образом:
P(xi) = V(x1, … xi-1, xi+1, …, xn), i=1, 2, …, n, (2)
Чем меньшее значение принимает величина P(xi), тем больший вклад в оценку качества V(x1, … , xn) всего набора признаков вносит признак xi, т.е. тем более весомым, более информативным, важным можно считать этот признак xi. Упорядочив признаки по возрастанию значений P(xi), можно получить их относительную важность для задачи распознавания в условиях конкретной ОВ.
Выводы
Выполнение указанных процедур позволяет оптимизировать начальные этапы подготовки данных при формировании ОВ, более осознанно подойти к ее созданию и отбору признаков, что может значительно сократить временные и прочие затраты при исследовании предметной области с помощью методов DM и BD и, самое главное, повысить эффективность решения поставленных задач.
Указанный подход с успехом может использоваться в решении целого ряда задач DM – 1) оценка информативности дискретных признаков, 2) оценка качества обучающей и экзаменационной выборок, 3) при поиске наиболее типичных объектов ОВ, 4) при поиске информативных групп дискретных признаков. В качестве примера можно привести сервисы по обработке и анализу данных на портале https://www.sciencehunter.net/Services.
Литература
- А.Ф.Лосев Дерзание духа. – М.: ИПЛ, 1988. – 364 с.
- Вертгеймер М. Продуктивное мышление. М., 1987.
- В.А.Смирнов Уровни знания и этапы процесса познания. В кн.: «Проблемы логики научного познания, М. 1964г, АН СССР, Институт философии.
- Дюкова Е.В., Песков Н.В. Поиск информативных фрагментов описаний объектов в дискретных процедурах распознавания // Ж. вычисл. матем. и ма-тем. физ. 2002. Том 42, № 5, С. 741-753.
- Д.Н. Олешко, В.А. Крисилов, А.А. Блажко Построение качественной обучающей выборки для прогнозирующих нейросетевых моделей //Искусственный интеллект» 3’2004, c.567- c.573.
- Кендалл М.Дж., А.Стьюарт Статистические выводы и связи. М.: Наука, 1973.
- Василенко Ю. А., Шевченко Г. Я. Аналитический метод нахождения тестов //Aвтоматика. – 1979.